



Guillaume Le Moing
Research Scientist, Google DeepMind
I am a Research Scientist at Google DeepMind in Paris. I completed in 2024 my PhD in computer vision at Willow, a joint research lab between the Department of Computer Science of École normale supérieure (ENS) and Inria Paris, collaborating with Cordelia Schmid and Jean Ponce. I am interested in computer vision, deep learning with topics around generative modeling and motion understanding. I have been working on controllable image and video synthesis, with downstream tasks like anticipating the future, and creative applications like content editing. I have received a MSc degree in Executive Engineering from École des Mines de Paris and a MSc degree in Artificial Intelligence, Systems and Data from PSL Research University.
News
Talks
Research


CVPR, 2026 (Best Paper 🏆).
@inproceedings{zhang2025d4rt,
title = {Efficiently Reconstructing Dynamic Scenes One D4RT at a Time},
author = {Zhang, Chuhan and Le Moing, Guillaume and Koppula, Skanda and Rocco, Ignacio and Momeni, Liliane and Xie, Junyu and Sun, Shuyang and Sukthankar, Rahul and Barral, Jo{\"e}lle K. and Hadsell, Raia and Ghahramani, Zoubin and Zisserman, Andrew and Zhang, Junlin and Sajjadi, Mehdi S. M.},
booktitle = {CVPR},
year = {2026}
}
Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks.


ICCV, 2025.
@inproceedings{hasson2025scivid,
title = {{SCIVID}: Cross-Domain Evaluation of Video Models in Scientific Applications},
author = {Hasson, Yana and Luc, Pauline and Momeni, Liliane and Ovsjanikov, Maks and Le Moing, Guillaume and Kuznetsova, Alina and Ktena, Ira and Sun, Jennifer J. and Koppula, Skanda and Gokay, Dilara and Heyward, Joseph and Pot, Etienne and Zisserman, Andrew},
booktitle = {ICCV},
year = {2025}
}
In recent years, there has been a proliferation of spatiotemporal foundation models in different scientific disciplines. While promising, these models are often domain-specific and are only assessed within the particular applications for which they are designed. Given that many tasks can be represented as video modeling problems, video foundation models (ViFMs) hold considerable promise as general-purpose domain-agnostic approaches. However, it is not known whether the knowledge acquired on large-scale but potentially out-of-domain data can be effectively transferred across diverse scientific disciplines, and if a single, pretrained ViFM can be competitive with domain-specific baselines. To address this, we introduce SciVid, a comprehensive benchmark comprising five *Sci*entific *Vid*eo tasks, across medical computer vision, animal behavior, and weather forecasting. We adapt six leading ViFMs to SciVid using simple trainable readout modules, establishing strong baselines and demonstrating the potential for effective transfer learning. Specifically, we show that state-of-the-art results can be obtained in several applications by leveraging the general-purpose representations from ViFM backbones. Furthermore, our results reveal the limitations of existing ViFMs, and highlight opportunities for the development of generalizable models for high-impact scientific applications. We release our code at this https URL to facilitate further research in the development of ViFMs.


arXiv preprint, 2024.
@article{carreira2024scaling,
title = {Scaling 4D Representations},
author = {Jo\~ao Carreira and Dilara Gokay and Michael King and Chuhan Zhang and Ignacio Rocco and Aravindh Mahendran and Thomas Albert Keck and Joseph Heyward and Skanda Koppula and Etienne Pot and Goker Erdogan and Yana Hasson and Yi Yang and Klaus Greff and Guillaume Le Moing and Sjoerd van Steenkiste and Daniel Zoran and Drew A. Hudson and Pedro V\'elez and Luisa Polan\'ia and Luke Friedman and Chris Duvarney and Ross Goroshin and Kelsey Allen and Jacob Walker and Rishabh Kabra and Eric Aboussouan and Jennifer Sun and Thomas Kipf and Carl Doersch and Viorica P\v{a}tr\v{a}ucean and Dima Damen and Pauline Luc and Mehdi S. M. Sajjadi and Andrew Zisserman},
journal = {arXiv preprint},
year = {2024}
}
Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks – action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model – 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.

CVPR, 2024 (Highlight ✨).
@inproceedings{lemoing2024dense,
title = {Dense Optical Tracking: Connecting the Dots},
author = {Guillaume Le Moing and Jean Ponce and Cordelia Schmid},
booktitle = {CVPR},
year = {2024}
}
Recent approaches to point tracking are able to recover the trajectory of any scene point through a large portion of a video despite the presence of occlusions. They are, however, too slow in practice to track every point observed in a single frame in a reasonable amount of time. This paper introduces DOT, a novel, simple and efficient method for solving this problem. It first extracts a small set of tracks from key regions at motion boundaries using an off-the-shelf point tracking algorithm. Given source and target frames, DOT then computes rough initial estimates of a dense flow field and visibility mask through nearest-neighbor interpolation, before refining them using a learnable optical flow estimator that explicitly handles occlusions and can be trained on synthetic data with ground-truth correspondences. We show that DOT is significantly more accurate than current optical flow techniques, outperforms sophisticated "universal" trackers like OmniMotion, and is on par with, or better than, the best point tracking algorithms like CoTracker while being at least two orders of magnitude faster. Quantitative and qualitative experiments with synthetic and real videos validate the promise of the proposed approach. Code, data, and videos showcasing the capabilities of our approach are available in the project webpage.

ICCV, 2023.
@inproceedings{lemoing2022waldo,
title = {{WALDO}: Future Video Synthesis using Object Layer Decomposition and Parametric Flow Prediction},
author = {Guillaume Le Moing and Jean Ponce and Cordelia Schmid},
booktitle = {ICCV},
year = {2023}
}
This paper presents WALDO (WArping Layer-Decomposed Objects), a novel approach to the prediction of future video frames from past ones. Individual images are decomposed into multiple layers combining object masks and a small set of control points. The layer structure is shared across all frames in each video to build dense inter-frame connections. Complex scene motions are modeled by combining parametric geometric transformations associated with individual layers, and video synthesis is broken down into discovering the layers associated with past frames, predicting the corresponding transformations for upcoming ones and warping the associated object regions accordingly, and filling in the remaining image parts. Extensive experiments on multiple benchmarks including urban videos (Cityscapes and KITTI) and videos featuring nonrigid motions (UCF-Sports and H3.6M), show that our method consistently outperforms the state of the art by a significant margin in every case. Code, pretrained models, and video samples synthesized by our approach can be found in the project webpage.

NeurIPS, 2021.
@inproceedings{lemoing2021ccvs,
title = {{CCVS}: Context-aware Controllable Video Synthesis},
author = {Guillaume Le Moing and Jean Ponce and Cordelia Schmid},
booktitle = {NeurIPS},
year = {2021}
}
This presentation introduces a self-supervised learning approach to the synthesis of new video clips from old ones, with several new key elements for improved spatial resolution and realism: It conditions the synthesis process on contextual information for temporal continuity and ancillary information for fine control. The prediction model is doubly autoregressive, in the latent space of an autoencoder for forecasting, and in image space for updating contextual information, which is also used to enforce spatio-temporal consistency through a learnable optical flow module. Adversarial training of the autoencoder in the appearance and temporal domains is used to further improve the realism of its output. A quantizer inserted between the encoder and the transformer in charge of forecasting future frames in latent space (and its inverse inserted between the transformer and the decoder) adds even more flexibility by affording simple mechanisms for handling multimodal ancillary information for controlling the synthesis process (e.g., a few sample frames, an audio track, a trajectory in image space) and taking into account the intrinsically uncertain nature of the future by allowing multiple predictions. Experiments with an implementation of the proposed approach give very good qualitative and quantitative results on multiple tasks and standard benchmarks.

CVPR, 2021.
@inproceedings{lemoing2021palette,
title = {Semantic Palette: Guiding Scene Generation with Class Proportions},
author = {Guillaume Le Moing and Tuan-Hung Vu and Himalaya Jain and Patrick P{\'e}rez and Matthieu Cord},
booktitle = {CVPR},
year = {2021}
}
Despite the recent progress of generative adversarial networks (GANs) at synthesizing photo-realistic images, producing complex urban scenes remains a challenging problem. Previous works break down scene generation into two consecutive phases: unconditional semantic layout synthesis and image synthesis conditioned on layouts. In this work, we propose to condition layout generation as well for higher semantic control: given a vector of class proportions, we generate layouts with matching composition. To this end, we introduce a conditional framework with novel architecture designs and learning objectives, which effectively accommodates class proportions to guide the scene generation process. The proposed architecture also allows partial layout editing with interesting applications. Thanks to the semantic control, we can produce layouts close to the real distribution, helping enhance the whole scene generation process. On different metrics and urban scene benchmarks, our models outperform existing baselines. Moreover, we demonstrate the merit of our approach for data augmentation: semantic segmenters trained on real layout-image pairs along with additional ones generated by our approach outperform models only trained on real pairs.
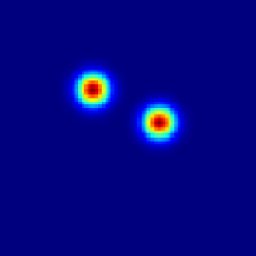
Guillaume Le Moing, Phongtharin Vinayavekhin, Don Joven Agravante, Tadanobu Inoue, Jayakorn Vongkulbhisal, Asim Munawar, Ryuki Tachibana
ICASSP, 2021.
@inproceedings{lemoing2021ssl,
title = {Data-Efficient Framework for Real-world Multiple Sound Source 2D Localization},
author = {Guillaume Le Moing and Phongtharin Vinayavekhin and Don Joven Agravante and Tadanobu Inoue and Jayakorn Vongkulbhisal and Asim Munawar and Ryuki Tachibana},
booktitle = {ICASSP},
year = {2021}
}